[Study] Computer Architecture
Study of Computer Architecture & Organization.
Introduction
My study notes of Computer Architecture & Organization. Took the class during 22-2. Note written during 22-Winter.
What is Computer?
The Von Neumann Architectue
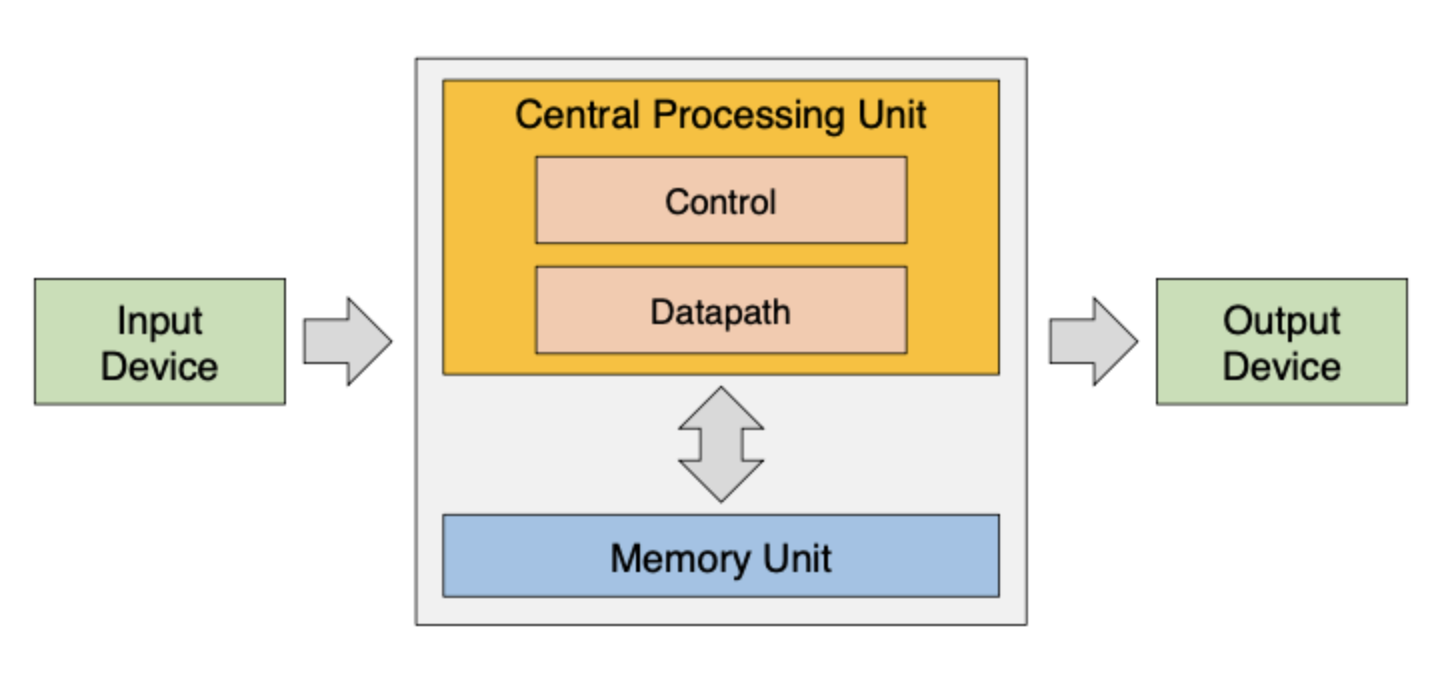 Just like coding, the basic architecture of a computer has an input -> process -> output.
Just like coding, the basic architecture of a computer has an input -> process -> output.
Typical computer organization
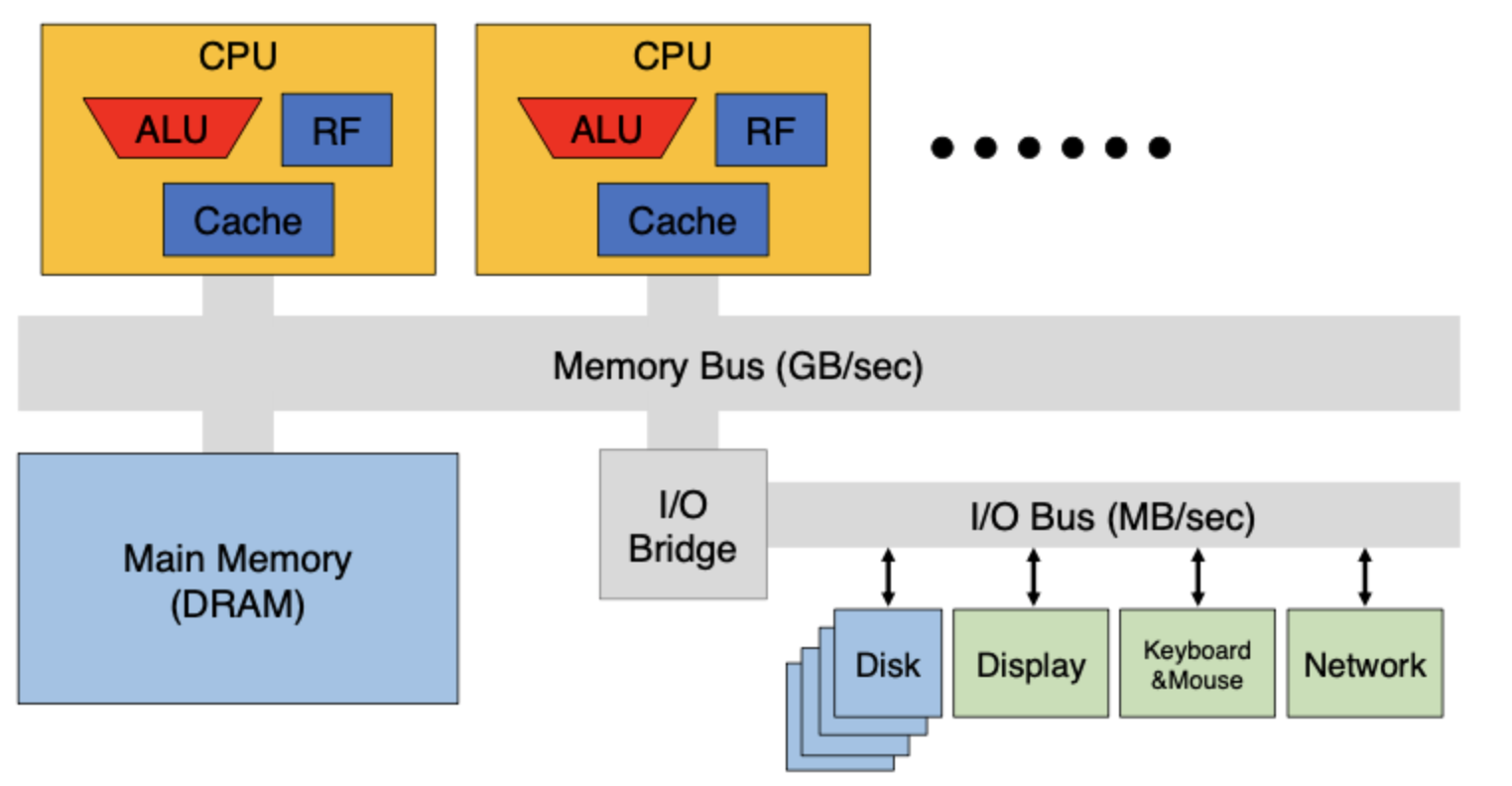
Instruction Set Architecture
ISA
- Processor’s Instruction set
- The set of assembly language instructions
- Programmer accessible register within processor
- Size of each programmer-accessible registers
- Instruction that can use each register
- Information necessary to interact with memory
- Memory alignment
- How processor reacts to interrupt from the programming view point
MIPS
- Goals of instruction set design for MIPS
- Maximize performance and minimize cost, and reduce design time (of compiler and hardware)
- By the simplicity of Hardware!
- MIPS design principles
- Simplicity favors regularity
- Smaller is faster
- Make the common case fast
- Good design demands goom compromises
Basic Procedures

How procedures are conducted. Control is transferred.
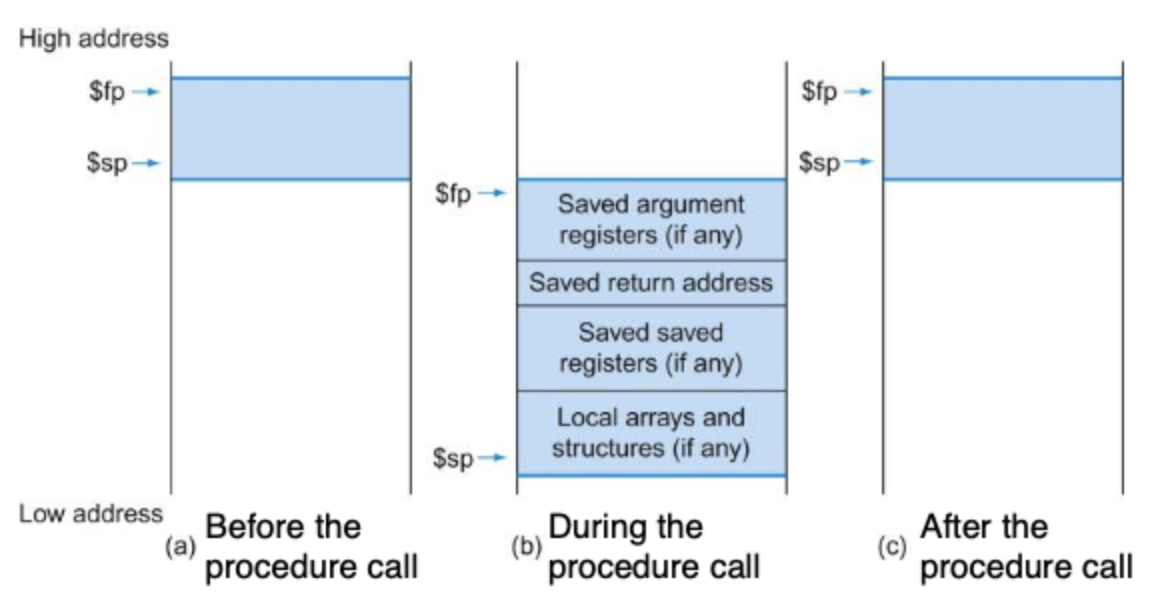
Uses stack to implement the design principles. Makes code simple, therefore making the common cases fast.
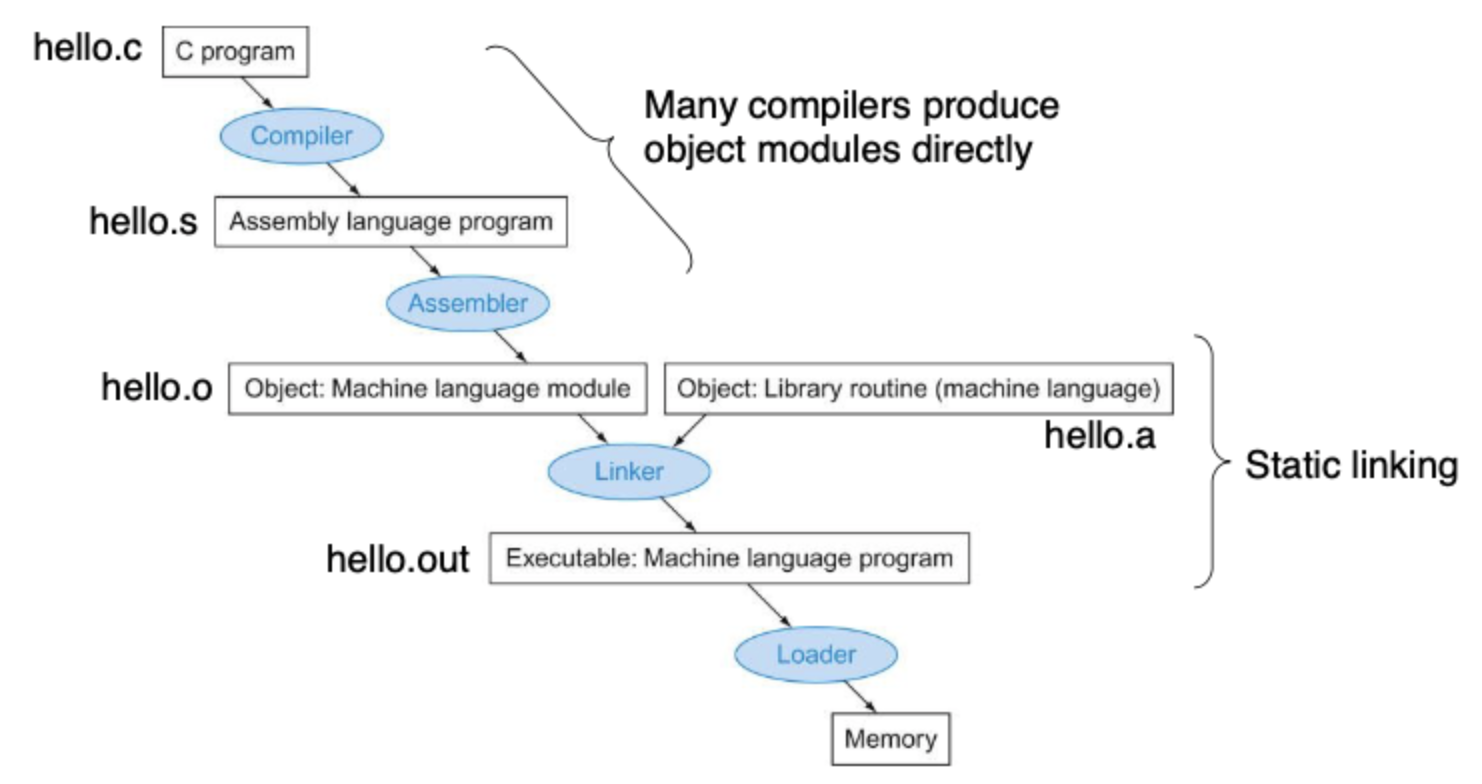
Translation and Startup
Like I learned in DS, the whole process is depicted as the following (In DS, the Linker & Loader was the focus; In CA, the Assembler was focused; Personally, I want to learn more about the Compiler..):
Loading a Program
Load from image file on disk into memory
- Read header to determine segment sizes
- Create virtual address space
- Done by the OS
- Virual address & memory explained later..
- Copy text and initialized data into memory
- Set up arguments on stack
- Initialize registers (including $sp; stack pointer, $fp; frame pointer, $gp; global pointer)
- Jump to startup routine
- Copies arguments to $a0, … and calls main
- When main returns, do exit syscall
Pipelining
Pipelined Datapath
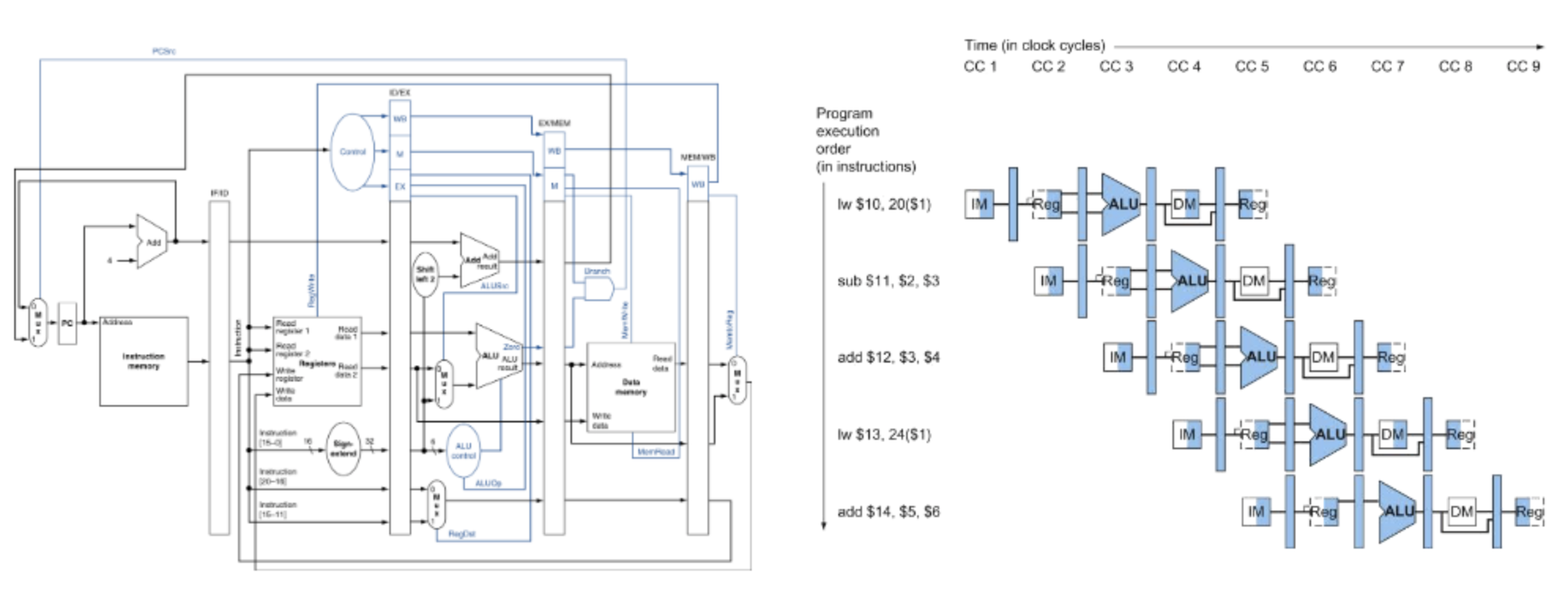
There exists 5 stages
- IF : Instruction Fetch
- ID : Instruction Decode
EX : Execute Operation Calculate Address - MEM : Access Memory
- WB : Write Result Back to Register
Control signals are also passed along the pipline because the next decoded instruction may overwrite the control signals. Saving the control preserves the action to be done.
Hazards
As instructions are executed continuously right after another, conflicts may happen.
- There exists 3 classes
- Structure Hazards
- A required resource is busy
- Data Hazards
- Need to wait for previous instruction to compelete its data read/write
- Solutions : forwarding, stalling, compiler scheduling
- Control Hazards :
- Deciding on control action depends on previous instruction
- Solutions : stall, reducing branch delay, branch prediction
Exceptions and Interrupts
- Exceptions
- “Unexpected” events within the CPU
- overflow, …
- “Unexpected” events within the CPU
- Interrupt
- From an external I/O controller
- Performance is sacrificed to deal with them
- Read the problem
- Transfer to related handler
- Determine the required action
- If restartable
- Take corrective action
- EPC (Exception Program Counter) to return to program
- Else terminate program
Performance
As one of the goals of DS, Algorithm, OS, etc. is efficiency, calculating performance is crucial.
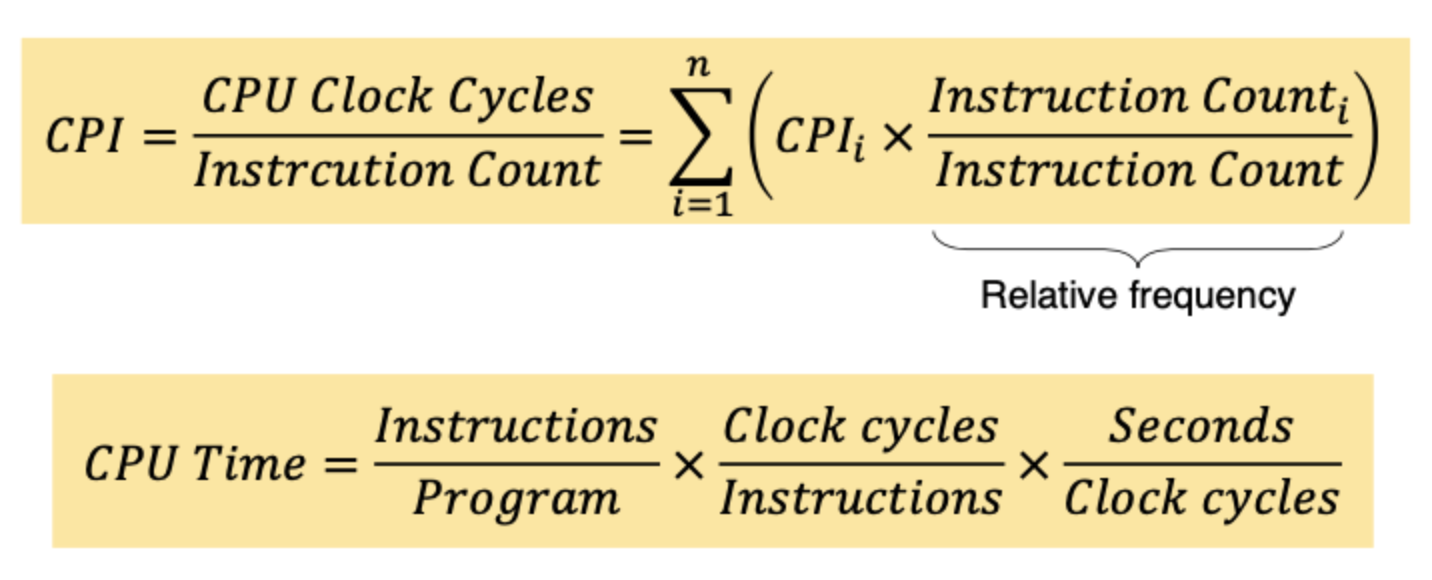
CPI : Clocks Per Instruction
Memory
Memory Hierarchy
Nothing to explain.. as intuitive as it can be.
Principle of Locality
- Temporal Locality
- Items accessed recently are likely to be accessed again soon
- e.g. loops
- Spatial Locality
- Items near those accessed reccently are likely to be accessed soon
- e.g. array data
Memory Heirarchy Levels
- Hit : access satisfied by upper level
- Miss : accessed data is absent so block copied from lower level.
Cache
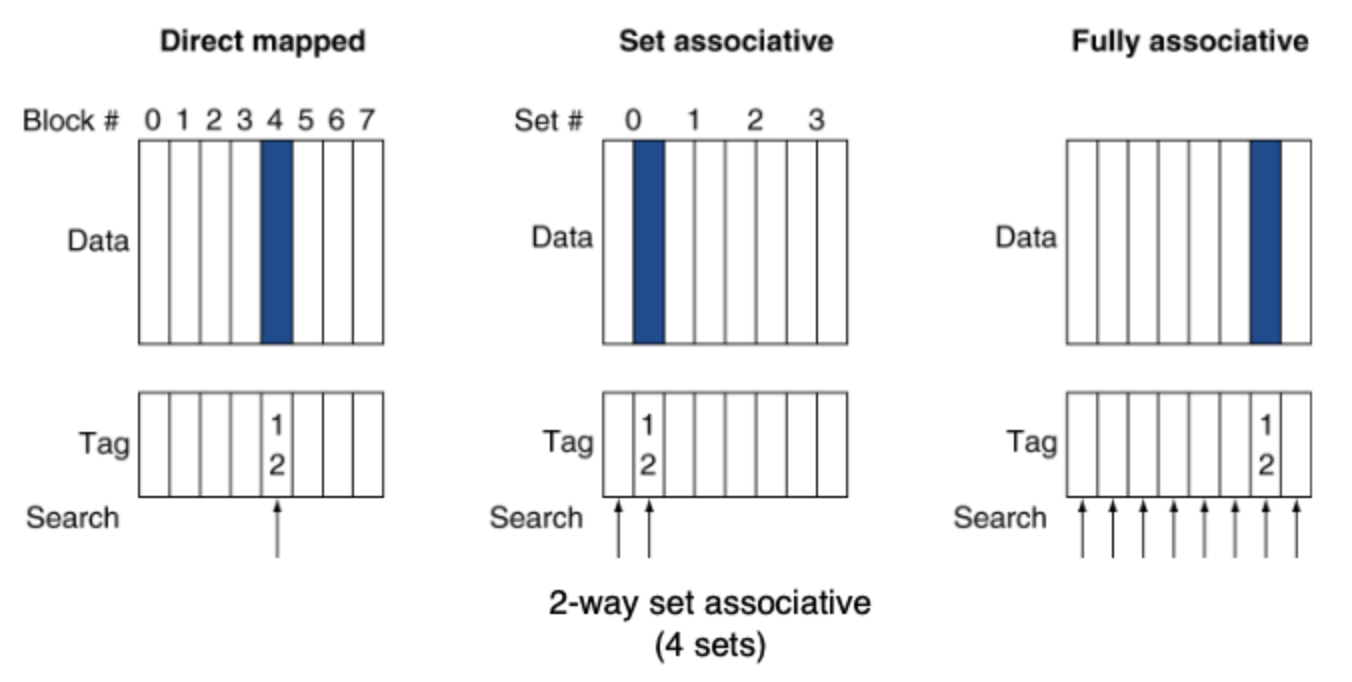
- Direct Mapped
- One tag per block.
- position of block = (num_block) % (num_cache_block)
- Set Associative
- Multiple tag per block.
- position of block = (num_block) % (num_cache_set)
Multilevel Caches
- Primary Cache
- Attached to CPU
- Small, but fast
- Level-2 Cache
- Services misses from primary cache
- Larger, slower, but still faster than main memory
- Main Memory
- Services misses from L-2 cache
- Some high-end systems include L-3 cache
Cache Coherence
- Suppose 2 CPU cores share a physical address space
- If CPU A writes 1 to X
- CPU A and CPU B’s content would be different
- [Snoop protocol] (https://www.techopedia.com/definition/332/snooping-protocol)
- If CPU A writes 1 to X
Writes
- On data-write hit
- Write Through
- Update cache & memory
- Write Back
- Update cache only
- Write Through
Virtual Memory
This topic is very important
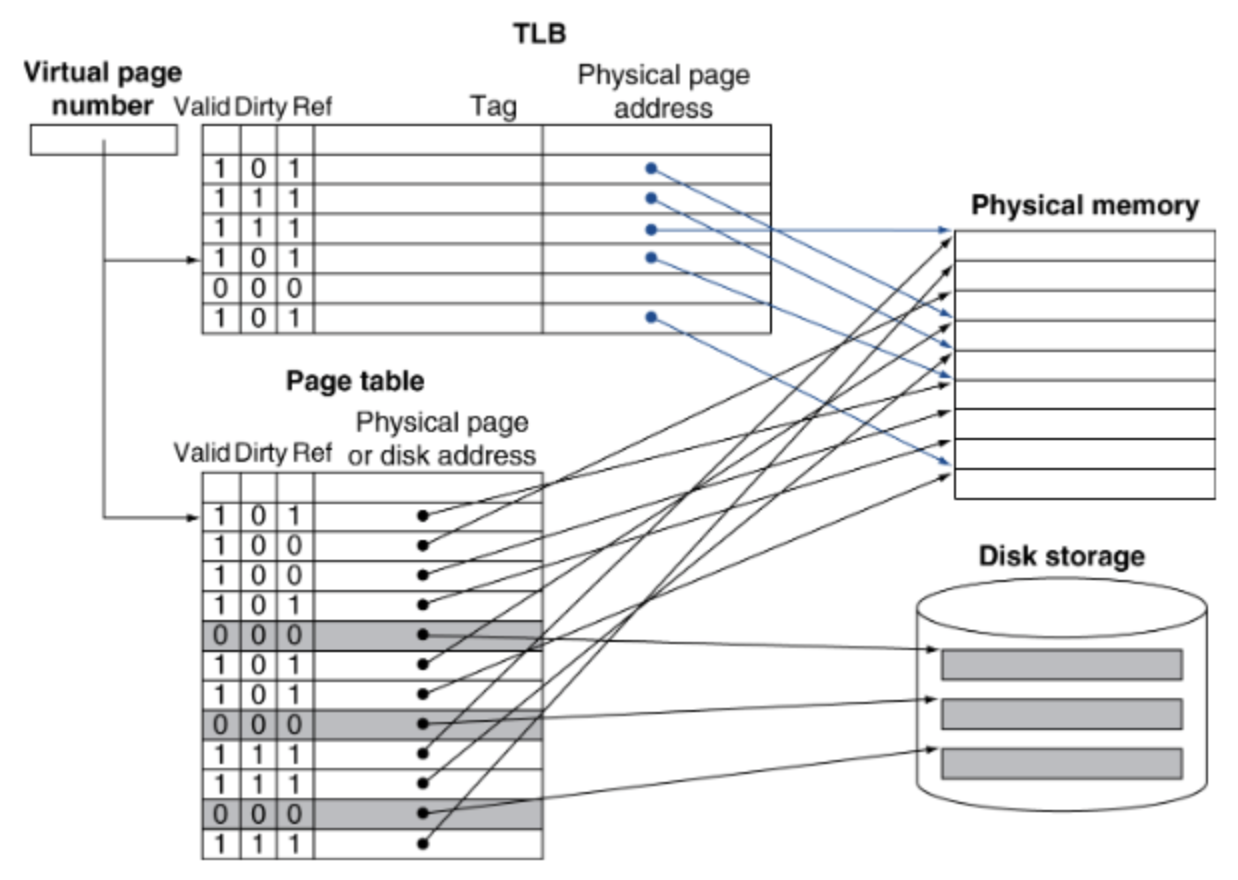
Virtual page number is used to access virtual address in TLB or/then Page table. Then the actual physical page address in the table is used to access Physical memory or Disk storage.
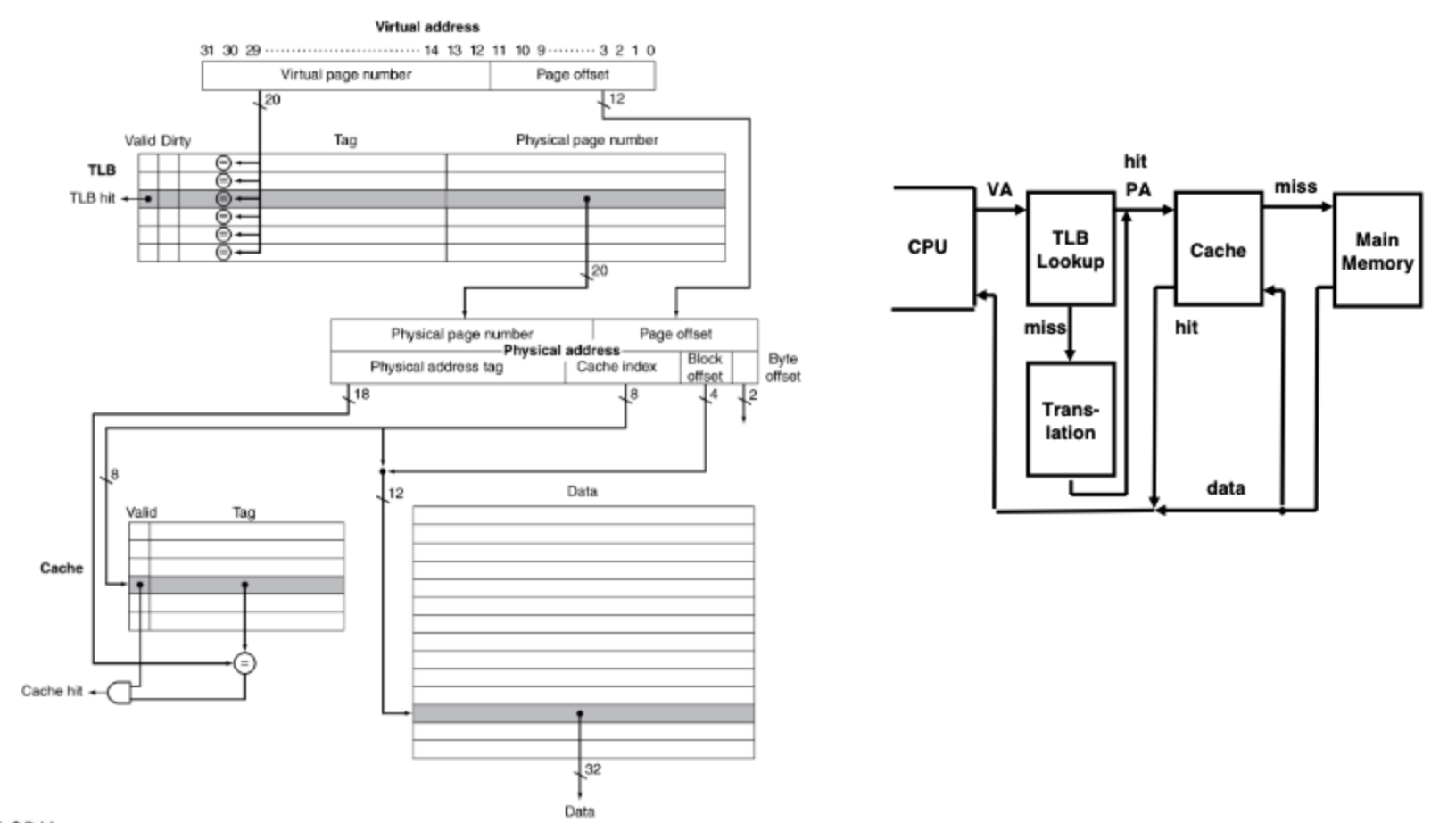
This second diagram shows a better picture of the flow.
SIMD
- Operate elementwise on vectors of data
- All processors execute the same instruction at the same time
- Simplifies synchronization
- Reduced instruction control hardware
- Works best for highly data-parallel applications
- e.g. GPU
BUS
- Shortened form of the Latin omnibus.
- Shared communication channel
- Parallel set of wires for data and synchronization of data transfer
- Can become a [bottleneck] (https://www.techopedia.com/definition/14630/von-neumann-bottleneck)
- Performance limited by physical factors
- Wire length, number of connections
- More recent alternative : high-speed serial connections with switches
- Like networks
I/O
Memory-Mapped I/O
- Certain adresses are not regular memory addresses
- Instead, they correspond to registers in I/O devices
- They are not accessed directly, only through through address + registers.
Polling and Interrrupt
- OS needs to know when
- I/O has completed an operation
- I/O has encountered an error
- Polling
- OS checks the status register to check if it is time for next I/O operation
- Interrupt
- When the I/O device completes an operation or needs attention, it “interrupts” the processor.
Multithreading
- Performing multiple [threads] (https://www.geeksforgeeks.org/thread-in-operating-system/) of execution in parallel
- Fine-grain Multithreading
- Switch threads after each cycle
- Coarse-grain Multithreading
- Only switch on long stall
- e.g. L-2 cache miss
- SMT
- Schedule instructions from multiple threads